1. ________ tools and techniques process data and do statistical analysis for insight and discovery.
Answer
Correct Answer:
Business Intelligence
Note: This Question is unanswered, help us to find answer for this one
2. ____ case tools provide support for the coding and implementation phases.
Answer
Correct Answer:
Back-end
Note: This Question is unanswered, help us to find answer for this one
3. The ______ of a worksheet defines its appearance.
Answer
Correct Answer:
Format
Note: This Question is unanswered, help us to find answer for this one
4. Dirty data is ________.
Answer
Correct Answer:
Inaccurate, incomplete data
Note: This Question is unanswered, help us to find answer for this one
5. Diigo and delicious are ________ tools.
Answer
Correct Answer:
Social bookmarking
Note: This Question is unanswered, help us to find answer for this one
6. Data types that are created by the programmer are known as ________.
Answer
Correct Answer:
Abstract data types (ADTs)
Note: This Question is unanswered, help us to find answer for this one
7. _______ reduces the number of bits in a file by identifying and eliminating redundancy
Answer
Correct Answer:
Lossless compression
Note: This Question is unanswered, help us to find answer for this one
8. Which of the following is the DMQL syntax that is used for specifying task-relevant data?
Answer
Correct Answer:
use database database_name
Note: This Question is unanswered, help us to find answer for this one
9.
Regression equation of Z on V is given as following:
Z = c +dV Using the least square method, which of the given normal equations will be used to calculate the values of c and d?
Answer
Correct Answer:
C)
Note: This Question is unanswered, help us to find answer for this one
10. Which of the following is the default value of the parameter HlSTORlCAL_MODEL_GAP used in Microsoft time series algorithm?
Answer
Correct Answer:
10
Note: This Question is unanswered, help us to find answer for this one
11.
Regression equation of Z on V is given as following:
7. = c + dV
The relationship between two variables a and b, is given as b + 6a = 20 and between another two variables c and d, as 4c + 10d = 50. The regression coefficient of c on a is given as 0.90. Find the regression coefficient of d on b.
Answer
Correct Answer:
3/50
Note: This Question is unanswered, help us to find answer for this one
12. If the significance level of a test is 5%, what will be the outcome of the test if p-value obtained is greater than 0.05?
Answer
Correct Answer:
Fail to reject null hypothesis
Note: This Question is unanswered, help us to find answer for this one
13. A parametric statistical model is given as: (S, P) with P = [P6 : e e 9]. Based on statistical notations, which of the following is the correct method of representing a?
Answer
Correct Answer:
e g R 0d
Note: This Question is unanswered, help us to find answer for this one
14. In Web Analytics, which of the following metrics is monitored in the Ecommerce Dashboard?
Answer
Correct Answer:
Total sale by products
Note: This Question is unanswered, help us to find answer for this one
15.
If median weight is 46. compute the missing frequency in the given table.
Answer
Correct Answer:
20
Note: This Question is unanswered, help us to find answer for this one
16.
The given data shows the relation between the number of students enrolled in an institute and their age.
Which of the following is the appropriate regression equation for the given data?
Answer
Correct Answer:
y = 4.261 +1.239x
Note: This Question is unanswered, help us to find answer for this one
17. If there is some data with missing values and you need to read a help file of a function, say median, then which of the following is the correct R syntax to do so?
Answer
Correct Answer:
?median
Note: This Question is unanswered, help us to find answer for this one
18. A user can obtain the pageviews of a website with the help of which of the following web analytics goals?
Answer
Correct Answer:
Destination goal
Note: This Question is unanswered, help us to find answer for this one
19. In association rule mining, which of the following statements is correct about Frequent Itemset Generation of the two-step approach?
Answer
Correct Answer:
Generates all itemsets whose support 5 minsup
Note: This Question is unanswered, help us to find answer for this one
20.
By default, which of the following events is/are set using the KlSSmetrics analytics tool?
(i) Visited site
(ii) Search engine hit
Answer
Correct Answer:
Both (i) and (ii)
Note: This Question is unanswered, help us to find answer for this one
21. Which Of the following t-tests should be performed in order to compare means from two different groups?
Answer
Correct Answer:
Independent samples t-test
Note: This Question is unanswered, help us to find answer for this one
22. In hypothesis testing. what will you call a population whose data is categorical and belongs to a collection Of discrete non-overlapping classes?
Answer
Correct Answer:
Multinomial
Note: This Question is unanswered, help us to find answer for this one
23.
Which of the given options is the correct way of representing the regression equation of Y on X. given that byx is regression coefficient of Y on X?
Answer
Correct Answer:
b)
Note: This Question is unanswered, help us to find answer for this one
24. Which of the following is the correct R command used for saving the contents of a workspace into the file. .RData?
Answer
Correct Answer:
save.image()
Note: This Question is unanswered, help us to find answer for this one
25. Which of the following options denotes the probability of avoiding a type-ll error in hypothesis testing?
Answer
Correct Answer:
1- (3
Note: This Question is unanswered, help us to find answer for this one
26.
In association rule mining, under tree projection, node P of a tree stores which of the following information?
(i)Itemset for node P
(ii)List of possible lexicographic extensions of P
(iii)Pointer to projected database of its child node
(iv)Bitvector containing information about which transactions in the projected database contain the
itemset
Answer
Correct Answer:
Only (0, (ii) and (iv)
Note: This Question is unanswered, help us to find answer for this one
27. In data mining, which of the following is the correct syntax of the foil method, FOIL_Prune, used for rule pruning for a rule R? It is given that p is the number of positive tuples covered by R and n is the number of negative tuples covered by R.
Answer
Correct Answer:
FOIL_Prune = p - n/p + n
Note: This Question is unanswered, help us to find answer for this one
28. In data mining, which of the following classification models is built by kNN algorithm?
Answer
Correct Answer:
No classification model is built by kNN
Note: This Question is unanswered, help us to find answer for this one
29. In the linear discriminant function of discriminant function analysis, what is the function Of the following method?
Answer
Correct Answer:
It prints discriminant functions based on variables that are centered, but not standardized.
Note: This Question is unanswered, help us to find answer for this one
30. In a generalized linear model. which of the following link functions belongs. by default, to Poisson family?
Answer
Correct Answer:
(link = "identity")
(link = "inverse")
(link = "logit")
(link = "log")
Note: This question has more than 1 correct answers
Note: This Question is unanswered, help us to find answer for this one
31.
The following code represents a function performed in data mining; identify the function represented.
mine comparison [as {pattern_name]}
For (target_class } where {t arget_condition )
{versus {contrast_class_i }
where [contrachondition_i]}
analyze [measure(s) ]
Answer
Correct Answer:
Discrimination
Note: This Question is unanswered, help us to find answer for this one
32. Which of the following is correct about classification of data?
Answer
Correct Answer:
It puts data in precise and condensed form. Ll Statistical analysis is possible for all types Of data except classified data.
Note: This question has more than 1 correct answers
Note: This Question is unanswered, help us to find answer for this one
33. Which of the following statements is/are correct about an SAS differentiator?
Answer
Correct Answer:
It is uniquely positioned to help organizations turn big data and big data analytics into business Value.
Note: This Question is unanswered, help us to find answer for this one
34. In data mining, which of the following parts of a decision tree represents the outcome ofa test?
Answer
Correct Answer:
A branch
Note: This Question is unanswered, help us to find answer for this one
35. Which of the following is the correct way of expressing null hypothesis of the lower tail test of the population mean? It is given that uo is a hypothesized lower bound of the true population mean
Answer
Correct Answer:
up 5 ll
Note: This Question is unanswered, help us to find answer for this one
36. For a given set of 25 items, coefficient of correlation between x and y is 0.6. The values of the arithmetic mean of x and y are 14 and 18, respectively, and the values of standard deviation of x and y are 4 and 6. respectively. If the pair (25. 18) has been wrongly taken as (18, 25). then find the correct value of correlation coefficient.
Answer
Correct Answer:
0.51
Note: This Question is unanswered, help us to find answer for this one
37. In association rule mining, an indication of how often the rule has been found to be true is represented by a term known as confidence. How is this term. confidence. represented for the rule, A => B?
Answer
Correct Answer:
conf(A => B) = supp(A U B) / supp(A)
Note: This Question is unanswered, help us to find answer for this one
38. In which of the key technologies, which are used for extracting business value from big data, data is managed as a strategic. core asset with ongoing process control for big data analytics?
Answer
Correct Answer:
Information management for big data
Note: This Question is unanswered, help us to find answer for this one
39. In data mining, which of the following models is/are used to predict the categorical class labels?
Answer
Correct Answer:
Classification model
Note: This Question is unanswered, help us to find answer for this one
40. Which of the following functions is used to decompose a time series with additive trend, and seasonal and irregular components?
Answer
Correct Answer:
stl0
Note: This Question is unanswered, help us to find answer for this one
41.
In logistic regression. which of the given methods is used to display the conditional density plot of the binary outcome, F. on the continuous x variable?
Answer
Correct Answer:
a)
Note: This Question is unanswered, help us to find answer for this one
42. It is given that y is a Poisson variate and satisfies the condition P(y=4) = P(y=5). What are the values of mean and standard deviation of y?
Answer
Correct Answer:
Mean = 5 and standard deviation = /’5
Note: This Question is unanswered, help us to find answer for this one
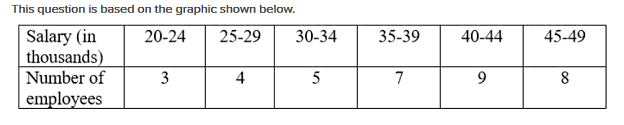
43.
For a group of employees of an organization, find the mean salary (in thousands) using the given data.
Answer
Correct Answer:
33.36
Note: This Question is unanswered, help us to find answer for this one
44. Which of the following statements is correct about the query-driven approach of data warehousing?
Answer
Correct Answer:
Complex integration and filtering processes are required by this approach.
Note: This Question is unanswered, help us to find answer for this one
45.
Consider the given data.
Find the regression equation Of Y on X and the total variation in Y.
Answer
Correct Answer:
Regression equation: Y = 2.25X +1.5, total variation in Y: 250
Note: This Question is unanswered, help us to find answer for this one
46. Which of the following clustering algorithms can handle noisy data?
Answer
Correct Answer:
CURE
Note: This Question is unanswered, help us to find answer for this one
47.
What is the function of the following R command?
dataframename.colnames <— namesfdataframename)
Answer
Correct Answer:
It is used to store the column names of a data frame in the variable. Dataframename.colnames.
Note: This Question is unanswered, help us to find answer for this one
48.
Data science is used in which of the following industries?
(i) Financial services
(ii) Digital advertisements
(iii) Healthcare
(iv) Image recognition
Answer
Correct Answer:
All the options (i). (ii). (iii) and (iv)
Note: This Question is unanswered, help us to find answer for this one
49.
Suppose a user has typed the following command, where mdata is a variable to which the user's data is stored. head(mdata)
Answer
Correct Answer:
6
Note: This Question is unanswered, help us to find answer for this one
50.
In which of the following types of reasoning in data science, the conclusions reached are probable,
reasonable. plausible and believable?
Deductive reasoning
Inductive reasoning
Answer
Correct Answer:
Only 2
Note: This Question is unanswered, help us to find answer for this one
51. Which of the following statements is NOT correct about data science?
Answer
Correct Answer:
In order to achieve success. organizations need to reach maximum data science maturity.
Note: This Question is unanswered, help us to find answer for this one
52. Which of the following is a descriptive function involved in data mining?
Answer
Correct Answer:
Mining of associations
Note: This Question is unanswered, help us to find answer for this one
53. In survival analysis, which of the following methods is used to model the hazard function on a set of predictor variables?
Answer
Correct Answer:
coxph()
Note: This Question is unanswered, help us to find answer for this one
54. Which of the following is the correct R syntax used for selecting certain rows from a data frame, based on specific logical criteria?
Note: This Question is unanswered, help us to find answer for this one
55. In data mining, which of the following is the correct syntax for defining recall, which is used to assess the quality of text retrieval?
Answer
Correct Answer:
Recall = l[Relevant} n [Retrieved}l / l[RelevantJI
Note: This Question is unanswered, help us to find answer for this one
56. Which of the following factors is responsible for the occurrence of sampling errors?
Answer
Correct Answer:
Faulty demarcation of sampling units.
Note: This Question is unanswered, help us to find answer for this one
57. Which of the following types of association mining discovers subsequences that are common to more than the minsup sequences in a sequence database?
Answer
Correct Answer:
Sequential pattern mining
Note: This Question is unanswered, help us to find answer for this one
58. In Google Analytics tool, which of the following analysis should be performed in order to identify the origin of a user's web traffic?
Answer
Correct Answer:
Acquisition analysis
Note: This Question is unanswered, help us to find answer for this one
59. If a user wants to learn about the top keywords that send traffic to his/her website, then which of the following acquisition segmentations should be preferred?
Answer
Correct Answer:
Organic traffic
Note: This Question is unanswered, help us to find answer for this one
60.
Consider the given information.
What should be the expenses budget (in Rs. thousands). if the salary of an individual is increased to Rs. 70 thousand?
Answer
Correct Answer:
11
Note: This Question is unanswered, help us to find answer for this one
61. In data mining, which of the following statements is NOT correct about C45 algorithm?
Answer
Correct Answer:
It allows only one outcome.
Note: This Question is unanswered, help us to find answer for this one
62. ln data mining, according to Bayes‘ theorem, which of the following formulae represents posterior probability in terms of prior probability?
Answer
Correct Answer:
P(H/X) = P(X/H)P(H)/P(X)
Note: This Question is unanswered, help us to find answer for this one
63. Which of the following commands is used for starting iPython interface in inline Pylab mode and opening iPython notebook in pylab environment?
Answer
Correct Answer:
ipython notebook —pylab=inline
Note: This Question is unanswered, help us to find answer for this one
64.
Which of the following challenges are faced in text mining?
(i) No publication is in electronic form.
(ii) Large textual database.
(iii) Complex relationships between concepts in text.
(iv) Limited number Of possible dimensions.
Answer
Correct Answer:
Only (ii) and (iii)
Note: This Question is unanswered, help us to find answer for this one
65. In which of the following Big Data technologies, moving relevant data management, analytics and reporting tasks to where the data resides, improves speed to insight, reduces data movement and promotes better data governance?
Answer
Correct Answer:
ln-database processing
Note: This Question is unanswered, help us to find answer for this one
66.
Which of the following commands is used to observe the way an R object is structured? It is given that mydata is a variable where a user's data is stored.
Answer
Correct Answer:
str(mydata)
Note: This Question is unanswered, help us to find answer for this one
67. In the Baysian model, which of the following is the correct representation of the joint density of (6, X), if it is known that for a given 0, the observed data x are a realization of pa?
Answer
Correct Answer:
n(0)p(xl0)
Note: This Question is unanswered, help us to find answer for this one
68. Which of the following statements is correct about the judgement sampling method?
Answer
Correct Answer:
It is mostly used in those fields where almost similar units exist or some units are tOO important' to be left out of the sample.
Note: This Question is unanswered, help us to find answer for this one
69. Which of the following statements are NOT correct about the Bayesian belief network?
Answer
Correct Answer:
VJ Joint conditional probability distribution cannot be specified by Bayesian belief networks. VJ A trained Bayesian network cannot be used for classification.
Note: This question has more than 1 correct answers
Note: This Question is unanswered, help us to find answer for this one
70. Which of the following is a non-probability sampling method?
Answer
Correct Answer:
Judgement sampling
Note: This Question is unanswered, help us to find answer for this one
71. Sam is popular for hitting a target in 6 out of 12 shots, whereas John can hit the same target in 8 out of 14 shots. What will be the probability that the target will be hit when they both try?
Answer
Correct Answer:
11/14
Note: This Question is unanswered, help us to find answer for this one
72. It is given that there are 15 pairs of readings on X and Y such that the coefficient of correlation is 0.87. It is also given that the standard deviation on is 5.60. What will be the approximate standard error of estimate of Y on X?
Answer
Correct Answer:
2.8
Note: This Question is unanswered, help us to find answer for this one
73. Which of the following clustering algorithms is used for grid-based partitioning?
Answer
Correct Answer:
STING
Note: This Question is unanswered, help us to find answer for this one
74. While calculating rank correlation coefficient between sales and expenditure for a time period of12 years. the difference in rank for a year was mistakenly taken as 9 instead of 7 and as a result, the value Of rank correlation coefficient was calculated as 0.79. If the mistake is rectified, then what will be the approximate correct value of rank correlation coefficient?
Answer
Correct Answer:
0.90
Note: This Question is unanswered, help us to find answer for this one
75. For a group of 12 students, the sum of squares of differences in their ranks for science and math is given as 60. On the basis of the given information. find the value of rank correlation coefficient.
Answer
Correct Answer:
0.79
Note: This Question is unanswered, help us to find answer for this one
76. The bag-of-words model is used in which of the following text mining processes?
Answer
Correct Answer:
Features generation
Note: This Question is unanswered, help us to find answer for this one
77. It is given that a and b are two independent binomial variables having parameters 3,114 and 2,1/4, respectively. Find P (a + b 21).
Answer
Correct Answer:
1023/1024
Note: This Question is unanswered, help us to find answer for this one
78. In association rule mining, an itemset is considered to be closed in which of the following situations?
Answer
Correct Answer:
When none of its immediate supersets has the same support as the itemset.
Note: This Question is unanswered, help us to find answer for this one
79.
Consider the following data:
Average cost of wafers = Rs. 35
Average cost of chocolates = Rs. 37
Standard deviation of cost of wafers = 2.0
Standard deviation of cost of chocolates = 3.0
Correlation coefficient between the costs of chocolates and wafers = 0.7
What will be the expected cost of chocolates when the cost of wafers is Rs. 40?
Answer
Correct Answer:
Rs. 42.25
Note: This Question is unanswered, help us to find answer for this one
80. While working in a Pylab environment, which of the following options do NOT need to be imported?
Answer
Correct Answer:
Both a and c
Note: This Question is unanswered, help us to find answer for this one
81.
Consider the following list:
squares_list = [2. 3. 5. 2. 8. 9. 7. 6}
What will be the output of the following Python command?
squares_list[-2]
Answer
Correct Answer:
7
Note: This Question is unanswered, help us to find answer for this one
82. Which of the following data mining algorithms is applied to a database containing a large number of transactions and also learns association rules?
Answer
Correct Answer:
Apriori
Note: This Question is unanswered, help us to find answer for this one
83. Which of the following fundamental measures used for assessing the quality of text retrieval represent(s) the percentage of retrieved documents relevant to a query?
Answer
Correct Answer:
Precision
Note: This Question is unanswered, help us to find answer for this one
84. Which of the following statements is NOT correct about pandas?
Answer
Correct Answer:
Only labelled data can be placed into a pandas data structure.
Note: This Question is unanswered, help us to find answer for this one
85.
Consider the following list:
squares_list = [2, 3. S. 2. 8. 9. 7. 6}
In which of the following IR models of text mining, a document is represented by a set of key terms that is either chosen from a fixed set of key terms or automatically from the documents?
Answer
Correct Answer:
Boolean model
Note: This Question is unanswered, help us to find answer for this one
86. Which of the following statements is incorrect about sampling methods?
Answer
Correct Answer:
No specialized knowledge is required to use a sampling method.
Note: This Question is unanswered, help us to find answer for this one
87. Which of the following sampling methods is used for heterogeneous units of universe rather than the homogeneous units and can be adopted only when its population is known?
Answer
Correct Answer:
Stratified random sampling
Note: This Question is unanswered, help us to find answer for this one
88.
Consider the following parameters:
Vector input = x
Total number of digits displayed = digits
Minimum number of digits to the right of the decimal point = nsmall
Minimum width to be displayed by the padding blanks in the beginning = width
Term to denote the option used to display scientific notation = scientific
Term to denote the option used to display the string left. right or center =justify
Option used for eliminating the space in between two strings = collapse
Separator between the arguments = sep
As per string manipulation in R programming language, which of the following options is the correct syntax Of the format() function for formatting numbers and strings?
Note: This Question is unanswered, help us to find answer for this one
89. Which of the following statements is correct about the NOT NULL modeling flag used in the Microsoft time series algorithm?
Answer
Correct Answer:
It applies to mining structure columns.
Note: This Question is unanswered, help us to find answer for this one
90. Which of the following options is the parameter of the Microsoft time series algorithm, which is used for controlling the growth of a decision tree?
Answer
Correct Answer:
COMPLEXITY_PENALTY
Note: This Question is unanswered, help us to find answer for this one
91. Which of the following options is the correct return type of the PredictHistogram (DMX) prediction function used by the Microsoft logistic regression algorithm?
Answer
Correct Answer:
Table
Note: This Question is unanswered, help us to find answer for this one
92. Which of the following options is the default CLUSTERING_METHOD used by the Microsoft clustering algorithm?
Answer
Correct Answer:
Scalable EM
Note: This Question is unanswered, help us to find answer for this one
93. As per Microsoft association rules algorithm, which of the following Options is the prediction function with scalar value as the return type?
Answer
Correct Answer:
PredictAdjustedProbability(DMX)
Note: This Question is unanswered, help us to find answer for this one
94. As per Microsoft association rules algorithm, which of the following prediction functions has/have a Boolean return type?
Answer
Correct Answer:
Both a and b
Note: This Question is unanswered, help us to find answer for this one
95.
Consider the following parameters:
control - Optional parameters for controlling boot data.
frequency - Specifies the number of observations per unit time.
data - Specifies the data frame.
bootobject - The Object returned by the boot function.
conf- The desired confidence interval.
type - The type of confidence interval returned.
According to bootstrapping in advanced statistics. which of the following options is the correct syntax of the boot.cio function?
Answer
Correct Answer:
boot.ci(bootobject. conf=. type=)
Note: This Question is unanswered, help us to find answer for this one
96. According to advanced statistics generalized linear model, which of the following is the default link function for the gaussian family?
Answer
Correct Answer:
(link = '’identity")
Note: This Question is unanswered, help us to find answer for this one
97. As per the Microsoft naive bayes algorithm, which two of the following options are the correct syntax of the Predict (DMX) prediction function?